
크롤링(1) - 네이버블로그 검색결과 크롤링
[파이썬 Beautifulsoup을 이용한 네이버블로그 검색결과 크롤링]
설치
pip install beautifulsoup
실습1) html 정보 가져오기
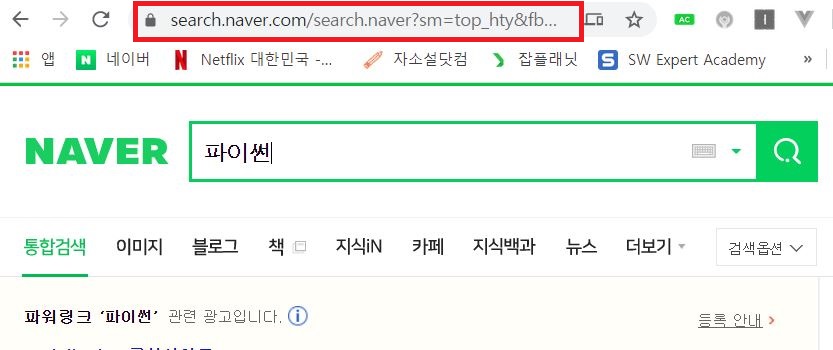
‘파이썬’이라고 검색 후 url을 복사
import urllib.request
from bs4 import BeautifulSoup
url = 'https://search.naver.com/search.naver?sm=top_hty&fbm=1&ie=utf8&query=%ED%8C%8C%EC%9D%B4%EC%8D%AC' # url주소
html = urllib.request.urlopen(url).read() #url 주소를 읽음
soup = BeautifulSoup(html,'html.parser')
print(soup)
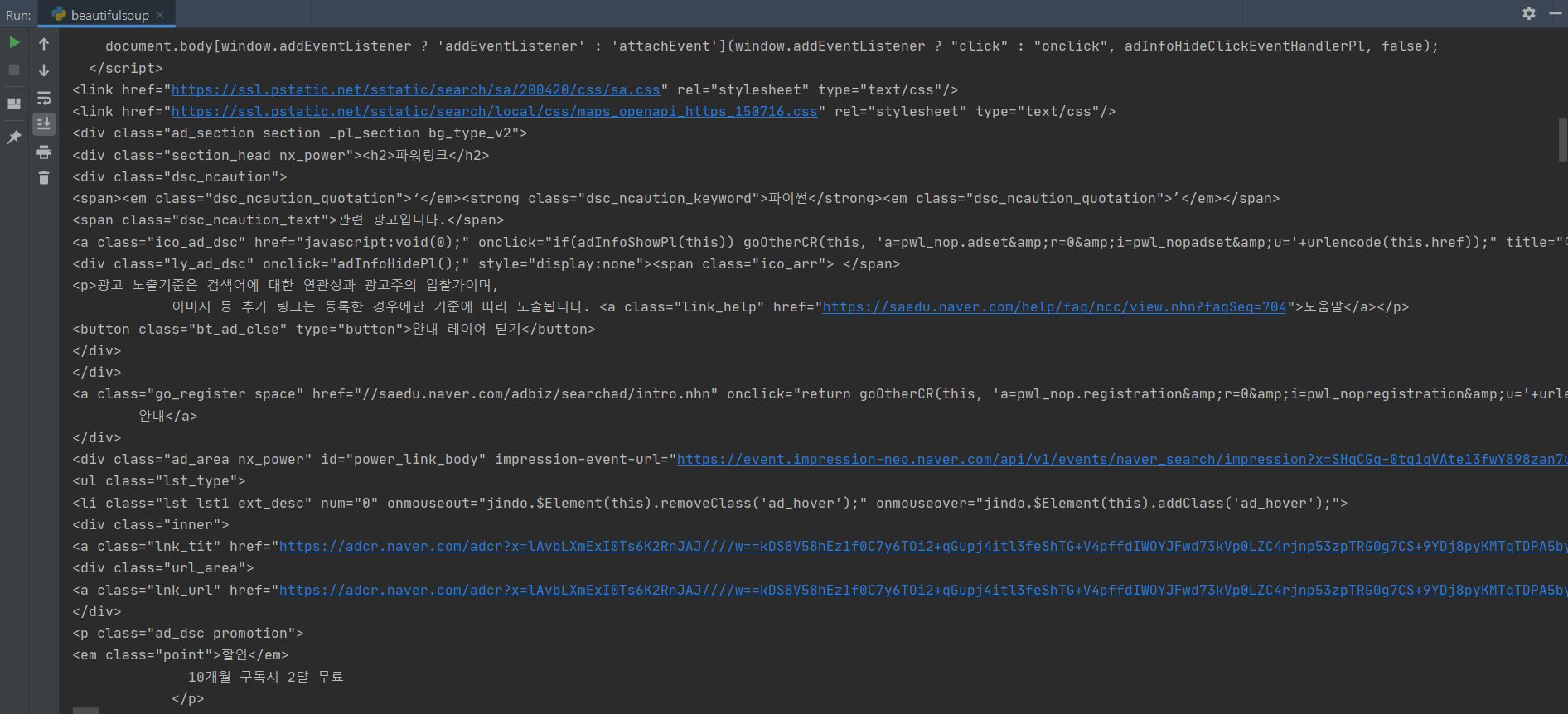
실행결과 : url에 있는 html 정보를 가져옴
실습2) 원하는 태그정보 가져오기
개발자 도구를 열어서 표시된 버튼을 누르고 마우스 커서를 옮기면 태그 정보를 보여줌
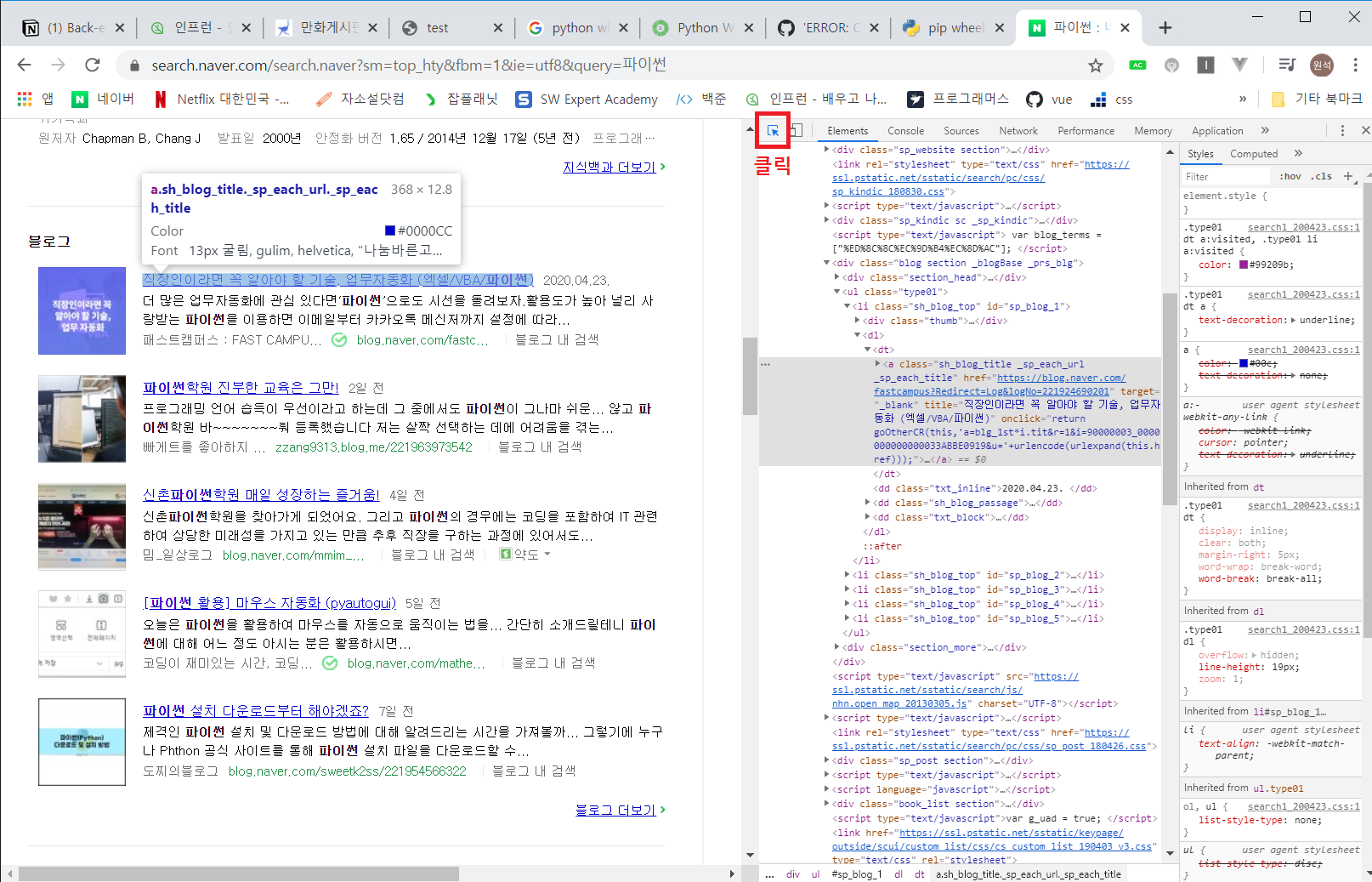
마우스를 올리면 블로그 제목마다 ‘sh_blog_title’ 클래스가 겹침
import urllib.request
from bs4 import BeautifulSoup
url = 'https://search.naver.com/search.naver?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC&where=post&sm=tab_nmr&nso='
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'html.parser')
title = soup.find_all(class_='sh_blog_title') #해당 클래스를 모두 찾음
print(title)
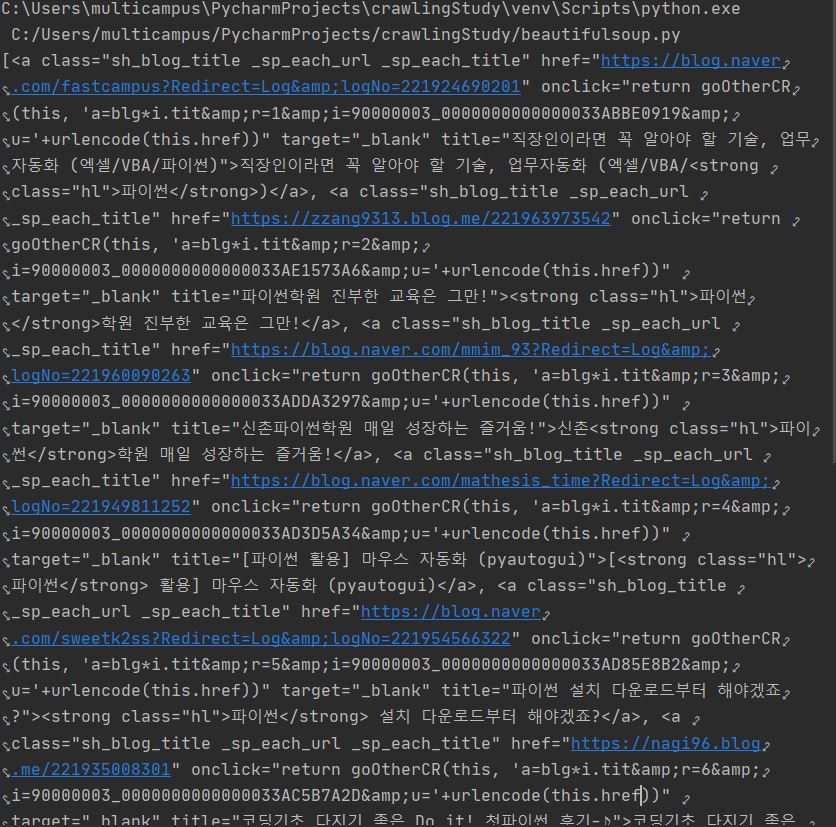
실행결과
여기서 ‘title’과 ‘href’ 태그 정보만 가져옴
for i in title:
print(i.attrs['title']) # attrs : 속성
print(i.attrs['href'])
실행결과
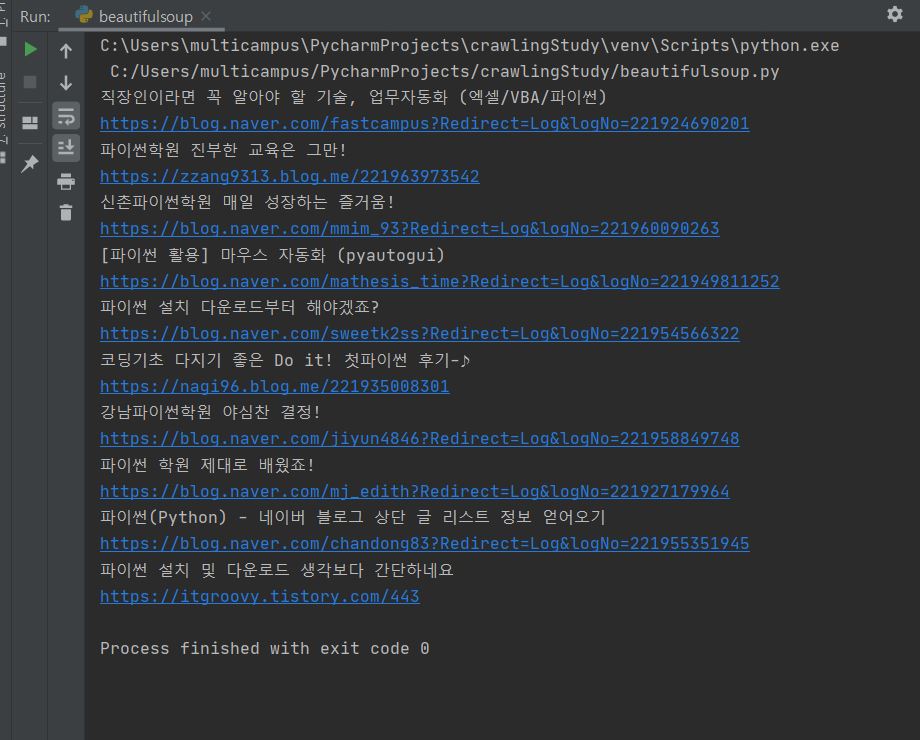
실습3) 베이스 url로 리팩토링
실습2의 문제점은 고정된 url을 사용하는 것이다.
다른 검색어로 검색할 때 매번 url을 따오지 않고 base url을 정해놓고 검색어마다 url을 바꿔줄 수 있다.
import urllib.request
from bs4 import BeautifulSoup
baseUrl = 'https://search.naver.com/search.naver?sm=tab_hty.top&where=post&query='
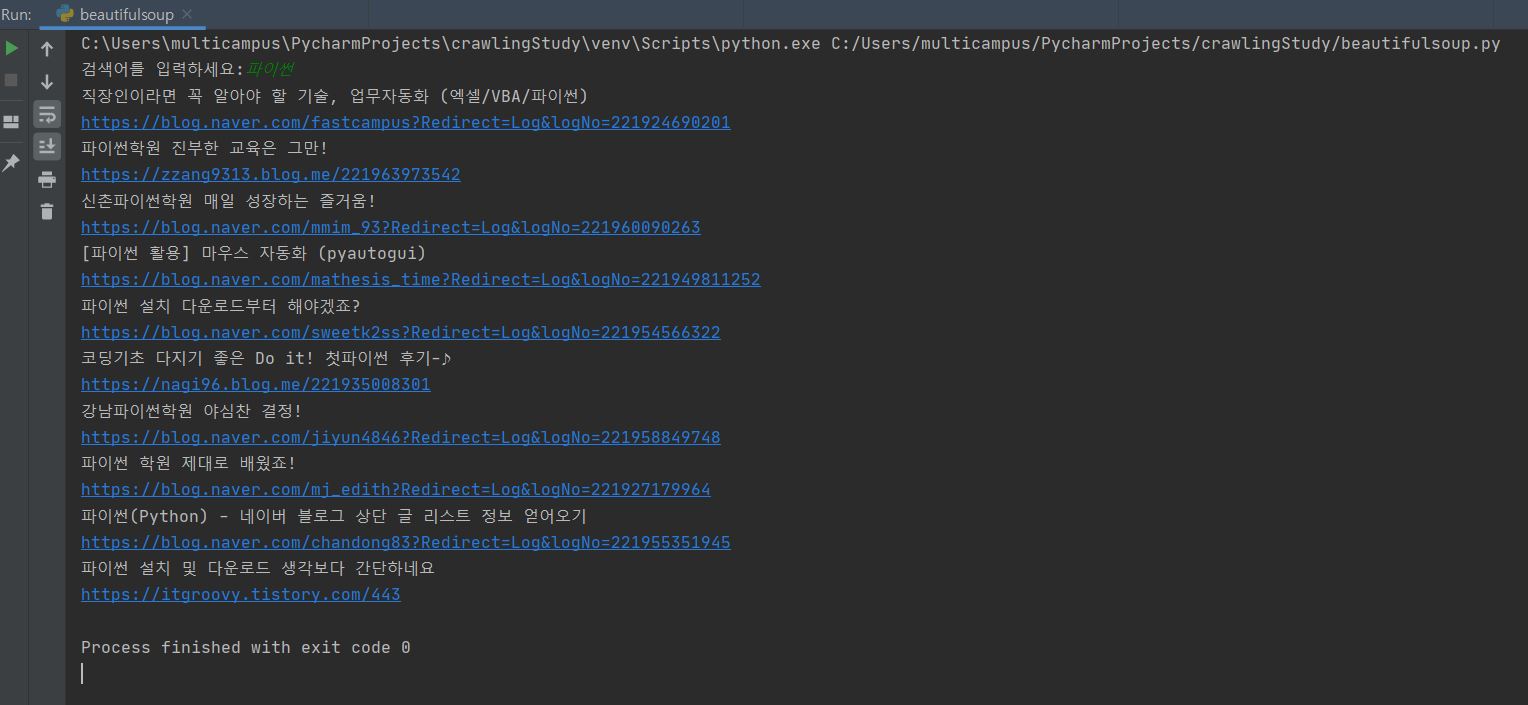
plusUrl = input('검색어를 입력하세요:')
url = baseUrl + plusUrl
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'html.parser')
title = soup.find_all(class_='sh_blog_title')
for i in title:
print(i.attrs['title'])
print(i.attrs['href'])
baseUrl를 정하고 plusUrl에 ‘파이썬’을 입력하고 Enter를 누르면…
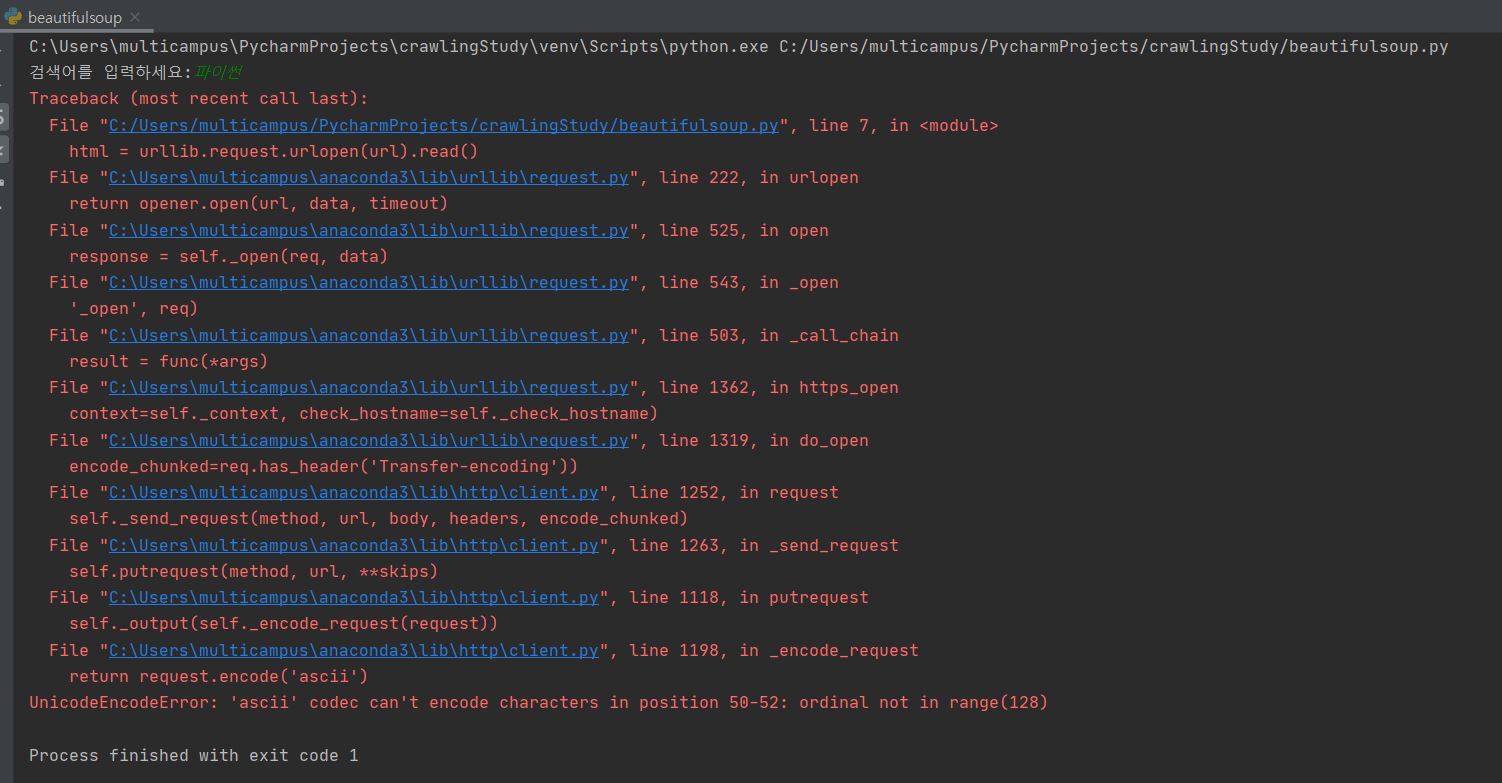
ascii 머시기 하면서 에러가 나옵니다.
‘파이썬’ 한글 검색어가 자동으로 변환되지 않아서 문제가 발생한건데
밑에 처럼 변경하면 잘 돌아갑니다.
import urllib.parse
url = baseUrl + urllib.parse.quote_plus(plusUrl)
Comments