
크롤링(2) - 이미지 검색결과 다운로드
[파이썬 Beautifulsoup을 이용한 이미지 검색결과 다운로드]
설치
pip install beautifulsoup
1) baseUrl 구하기
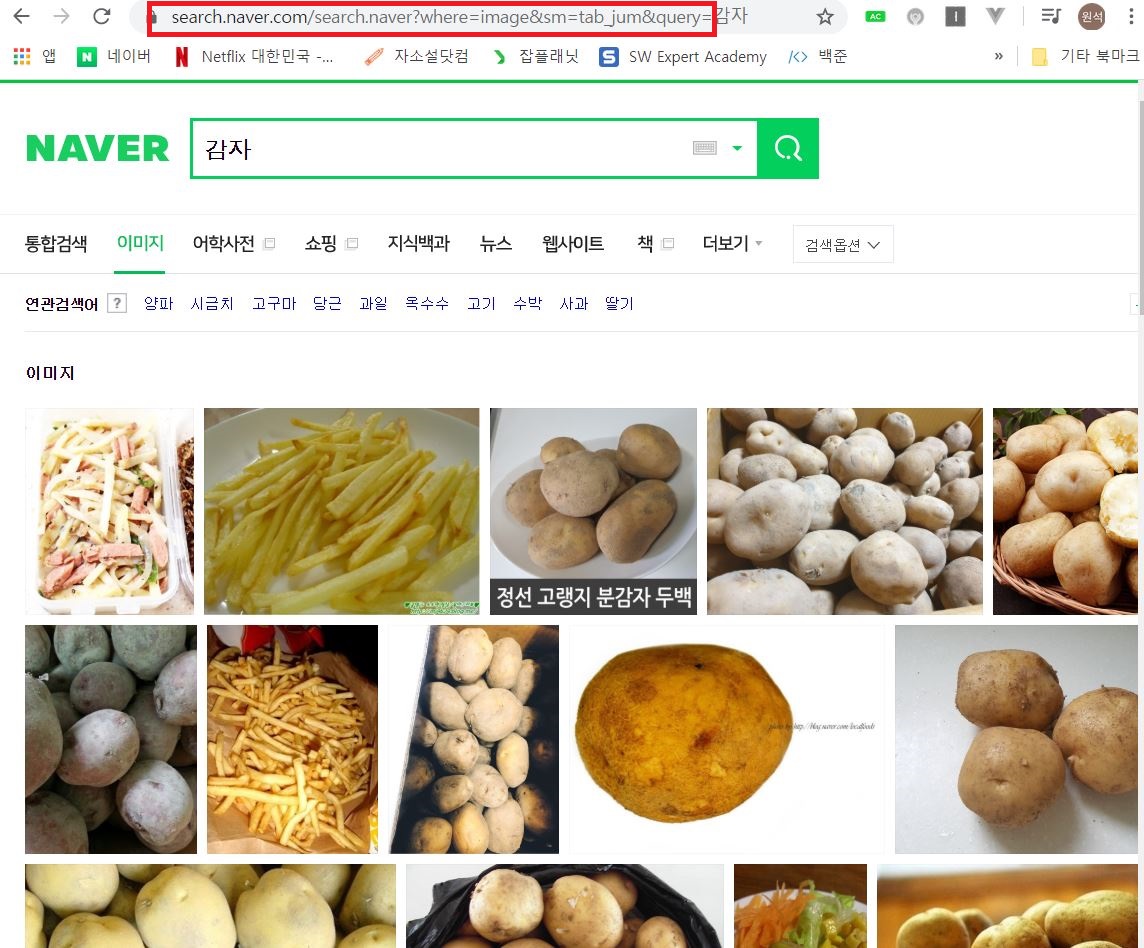
2) 태그 구하기
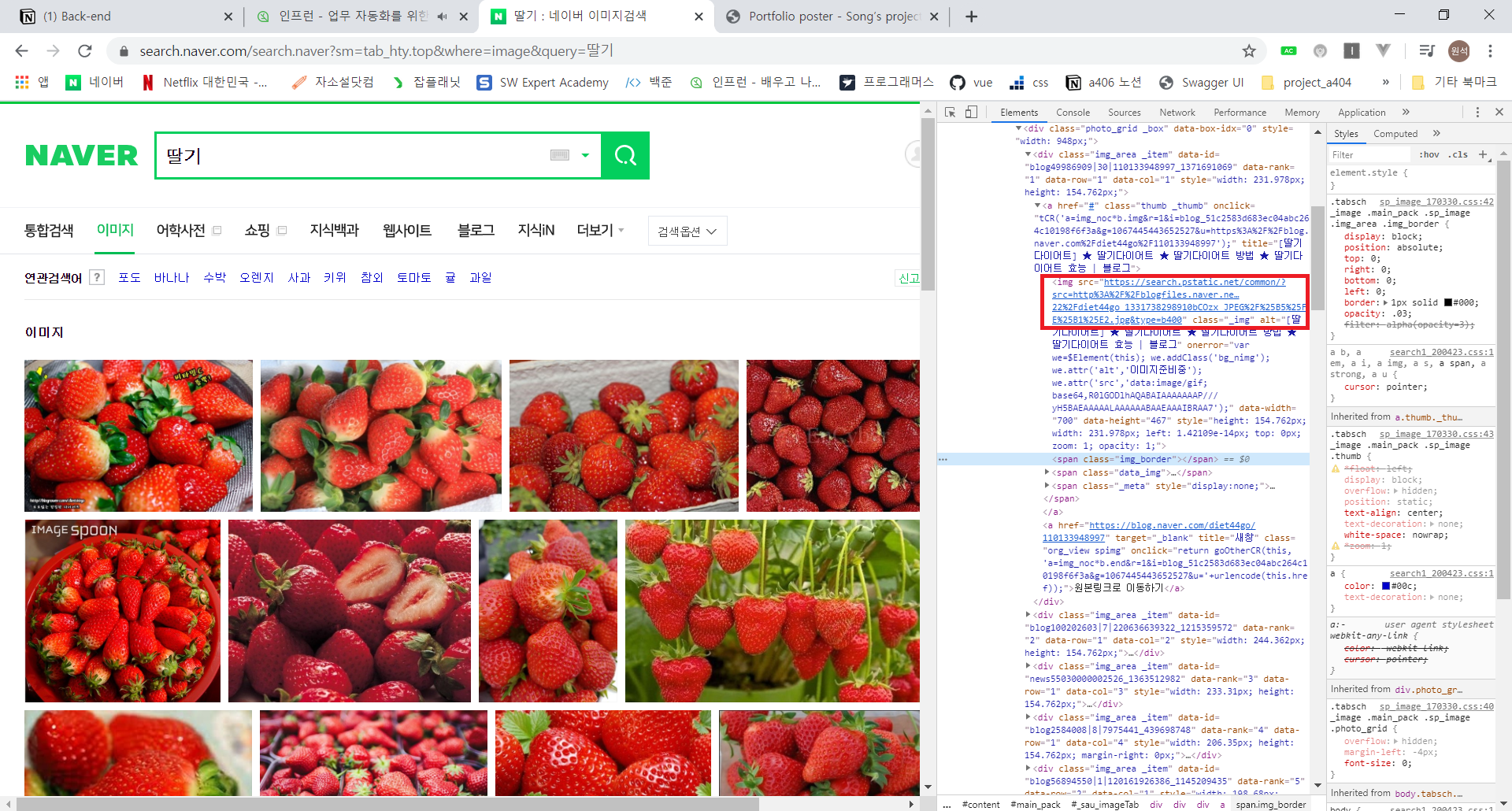
개발자 도구로 마우스 커서를 올리면 ‘_img’ 클래스 태그 확인할 수 있다.
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
baseUrl = 'https://search.naver.com/search.naver?where=image&sm=tab_jum&query='
plusUrl = input('검색어를 입력하세요:')
url = baseUrl + quote_plus(plusUrl) # 한글을 ascii 코드로 변환
html = urlopen(url).read()
soup = BeautifulSoup(html,'html.parser') # 'html 분석
img = soup.find_all(class_='_img')
실행결과
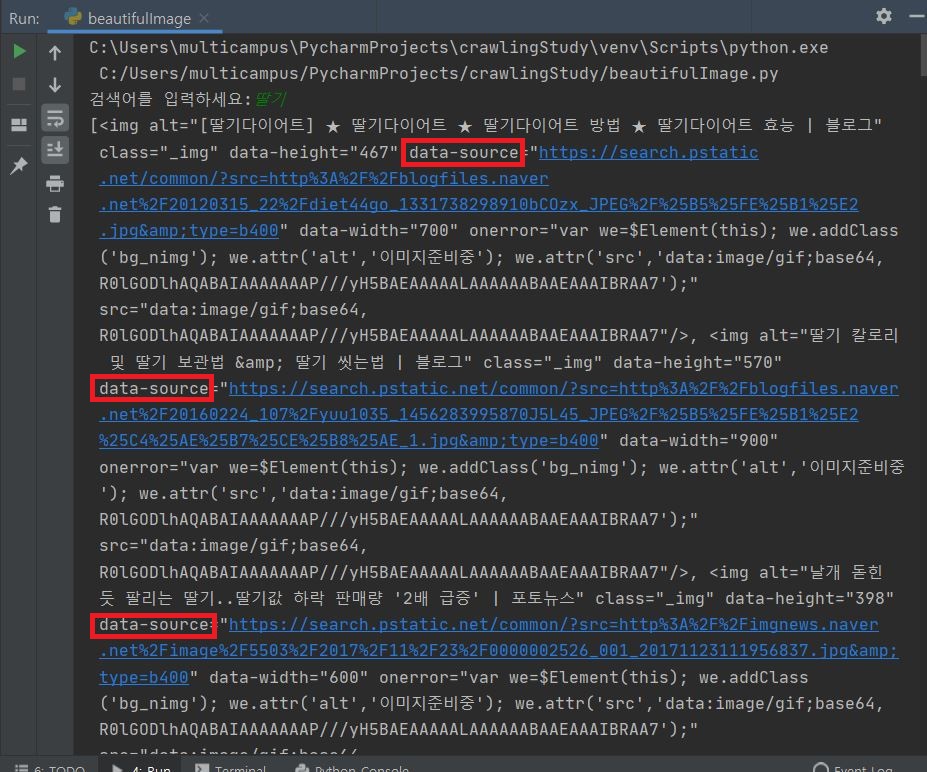
개발자 모드에선 img src에 이미지주소가 있었는데 실제 소스코드에는 data-source에 주소가 있음
javascript를 사용해서 변화되기 때문에 실제 소스와는 다름
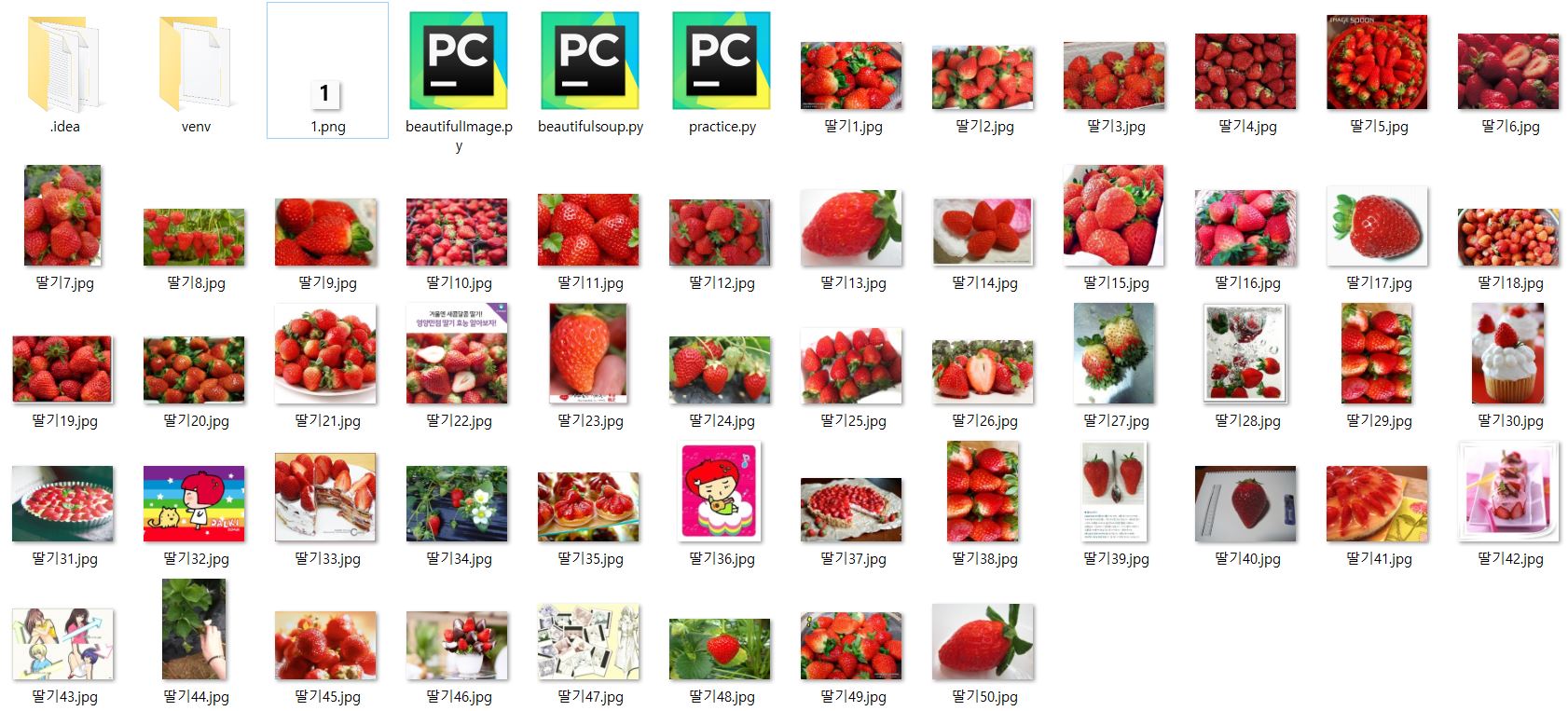
3) 이미지 저장
‘사과1.jpg, 사과2.jpg … 사과n.jpg’ 형식으로 저장
img = soup.find_all(class_='_img')
n = 1
for i in img:
imgUrl = i['data-source']
with urlopen(imgUrl) as f:
with open(plusUrl + str(n) + '.jpg','wb') as h :
img = f.read() # imgUrl을 읽어옴
h.write(img) # h로 저장
n += 1
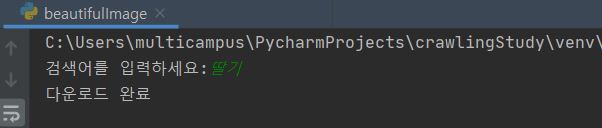
print('다운로드 완료')
with open(파일 경로, 모드) as 파일 객체:
‘wb’ -> w: 쓰기 , b : 이미지 -> 바이너리파일
실행결과
Comments