
추천 시스템(2) - Content-based filtering 구현
[영화 장르를 이용한 Content-based filtering 구현하기]
Table of Contents
-
영화 장르 필터링 구현 (Content-based Filtering)
영화 장르로 필터링하기
- 내용기반 필터링 (Content-Based Filtering)
- 실제 개발은 장르 + 감독으로 추천하는 서비스를 만들었지만 이해를 돕기 위해 장르 데이터로 필터링을 했음
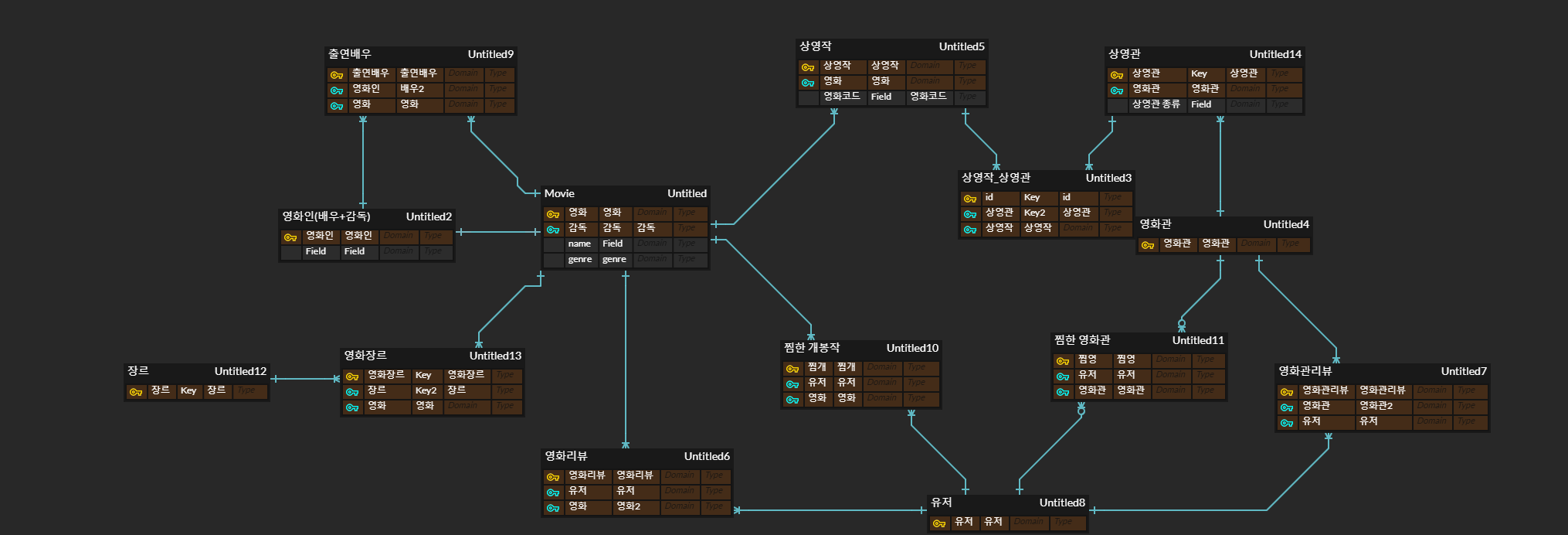
ERD 다이어그램
Install
pip install numpy
pip install pandas
pip install scikit-learn
pip install matplotlib
pip install seaborn
Import
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform as sp_rand
Read Data
ratings = pd.read_csv('./data/wouldyouci/ratings.csv')
genres = pd.read_csv('./data/wouldyouci/genres.csv', index_col='id')
# id컬럼 drop
movie_genres = pd.read_csv('./data/wouldyouci/movie_genre.csv',index_col='movie_id')
movie_genres = movie_genres.drop('id',axis='columns')
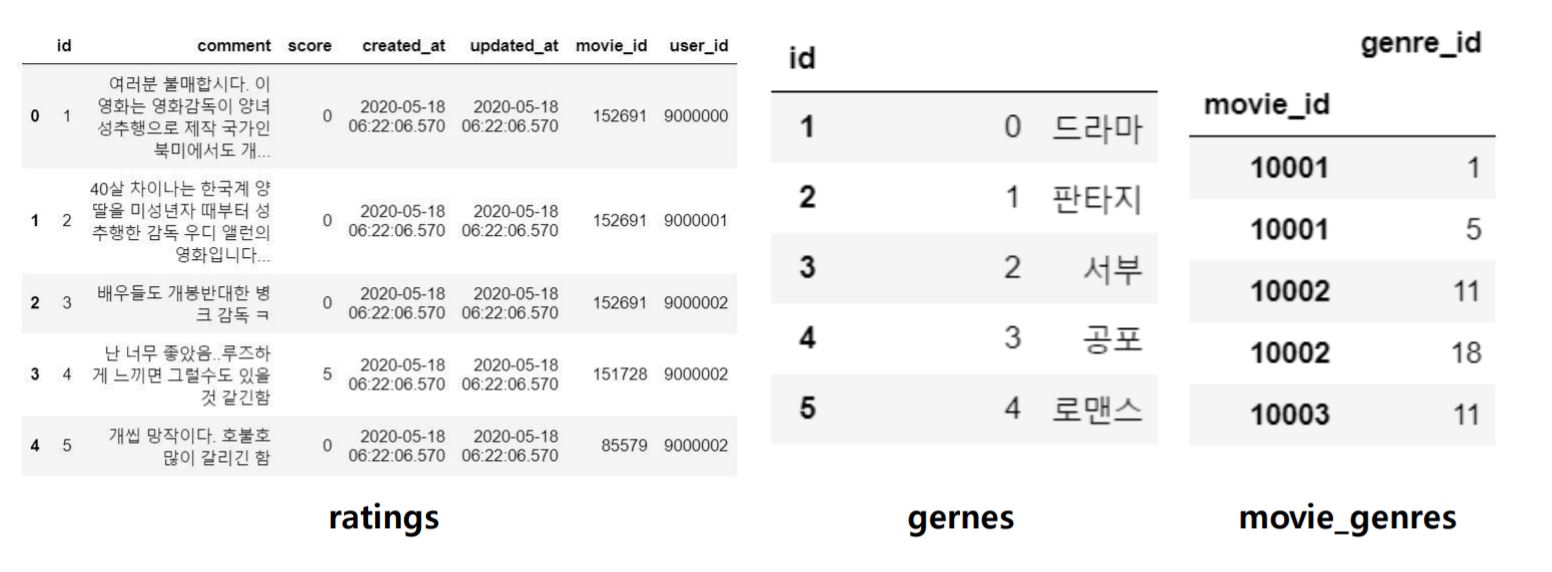
장르 분석
movie_genres['genre_id'] = movie_genres['genre_id'].apply(lambda x: genres.loc[x, 'name']+"|")
movie_genres = movie_genres.rename(columns={'genre_id' :'genre'})
# 장르들을 이어붙임
movie_genres = movie_genres.groupby('movie_id').sum()
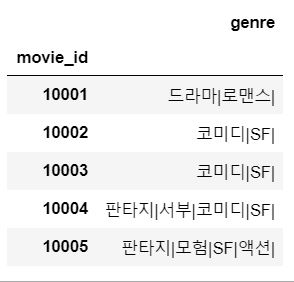
장르 데이터 숫자형으로 변환하기
genres_dummies = movie_genres['genre'].str.get_dummies(sep='|')
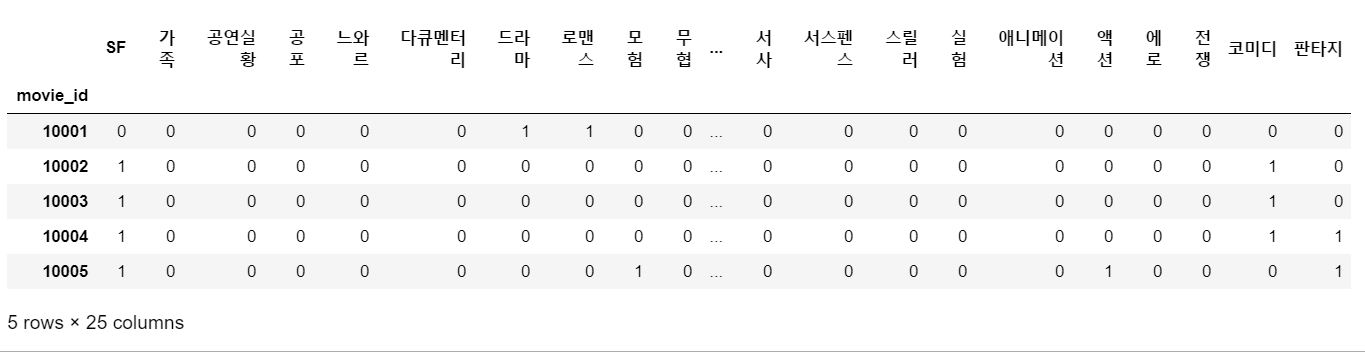
Pickle 파일로 만들기
path = os.path.join(BASE_DIR, 'genres_train.p')
genres_dummies.to_pickle(path)
영화평점 예측하기
# uesr_id = 9001839
tester = ratings[ratings['user_id'] == 9001839]
# 위에 저장했던 pickle 파일을 읽어와서 merge 시켜줌
genres = pd.read_pickle('./genre_train.p')
tester = tester.merge(genres, left_on='movie_id', right_index=True)
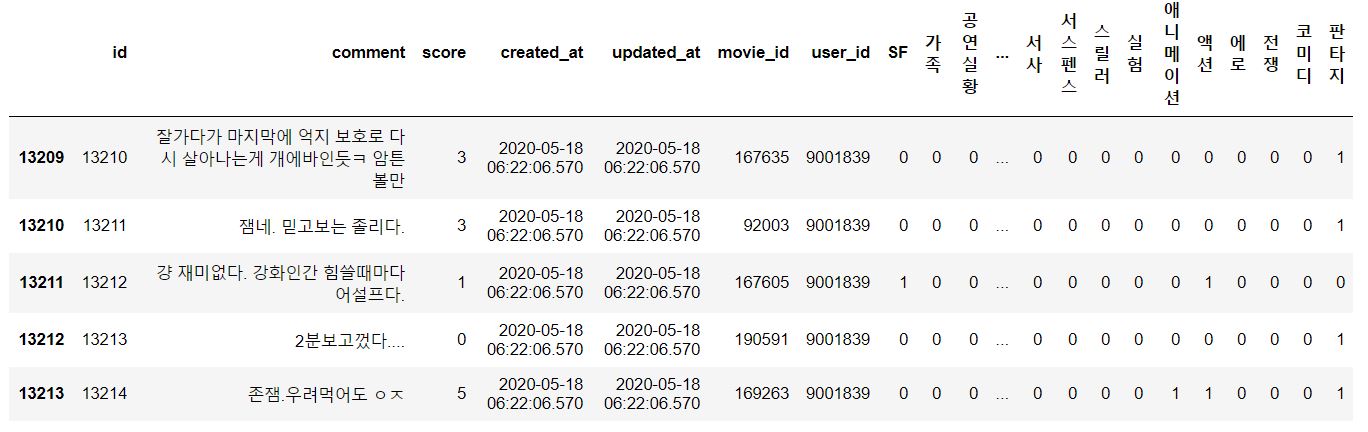
유저가 평가한 리뷰의 장르 분포
tester[genres.columns].sum().sort_values(ascending=False)

x_train, x_test, y_train, y_test = train_test_split(tester[genres.columns],
tester['score'],
random_state=406,
test_size=.1)
- 전체 데이터를 학습을 위한 데이터, 평가를 위한 데이터로 나누어 측정
- x축: 장르, y축 : 리뷰평점
- test_size를 0.1로 해두면 train : test 데이터 분포가 9:1로 설정됨
회귀모형
선형회귀: LinearRegression
reg = LinearRegression()
# 학습
reg.fit(x_train,y_train)
intercept = reg.intercept_
coef = reg.coef_
# 유저 프로필
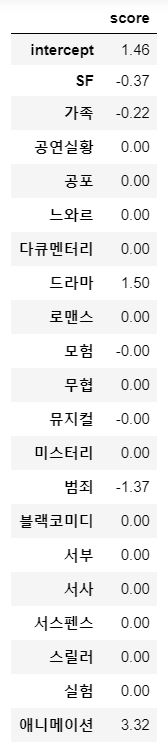
uesr_profile = pd.DataFrame([intercept, *coef], index=['intercept', *genres.columns], columns=['score'])
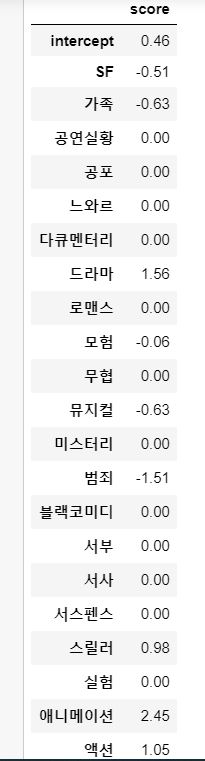
그래프로 보기
%matplotlib inline
# 한글 깨져서 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.figure(figsize=(25,7))
sns.barplot(data=uesr_profile.reset_index(), x='index', y='score')
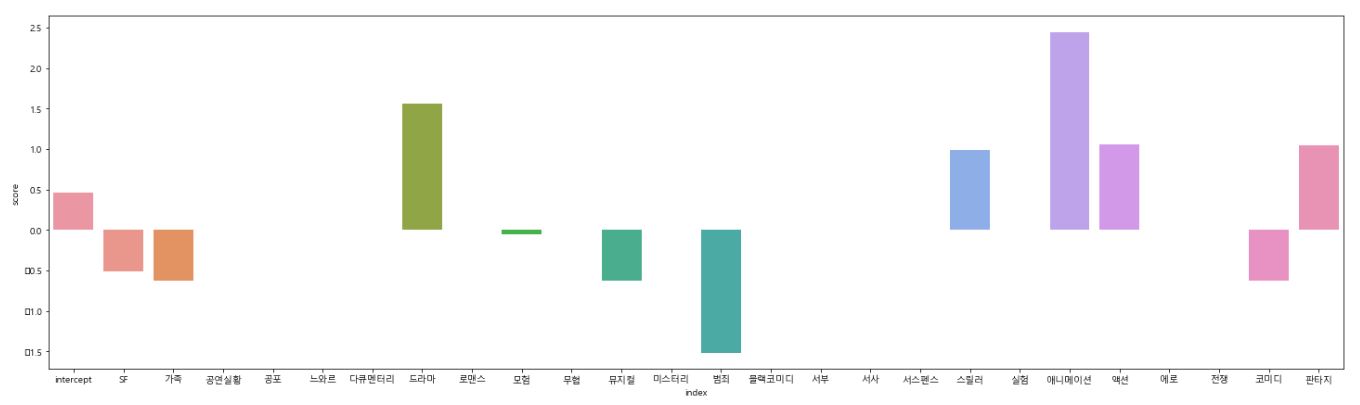
애니메이션과 드라마에 좋은 점수를 주는 것을 알 수 있음
RMSE(Root Mean Square Error) 구하기
predict = reg.predict(x_test)
mse = mean_squared_error(y_test,predict)
rmse = np.sqrt(mse)
# 낮을수록 좋음
# rmse = 0.5569105691056957
문제는?
- 데이터 갯수가 작은 user에게 coefficient 계산이 정확하지 않음, 또는 테스트 데이터만 설명할 수 있음 ( 오버피팅)
- 정규화(regularization)를 통한 과적합(Overfitting) 방지
제 1정규화: Lasso
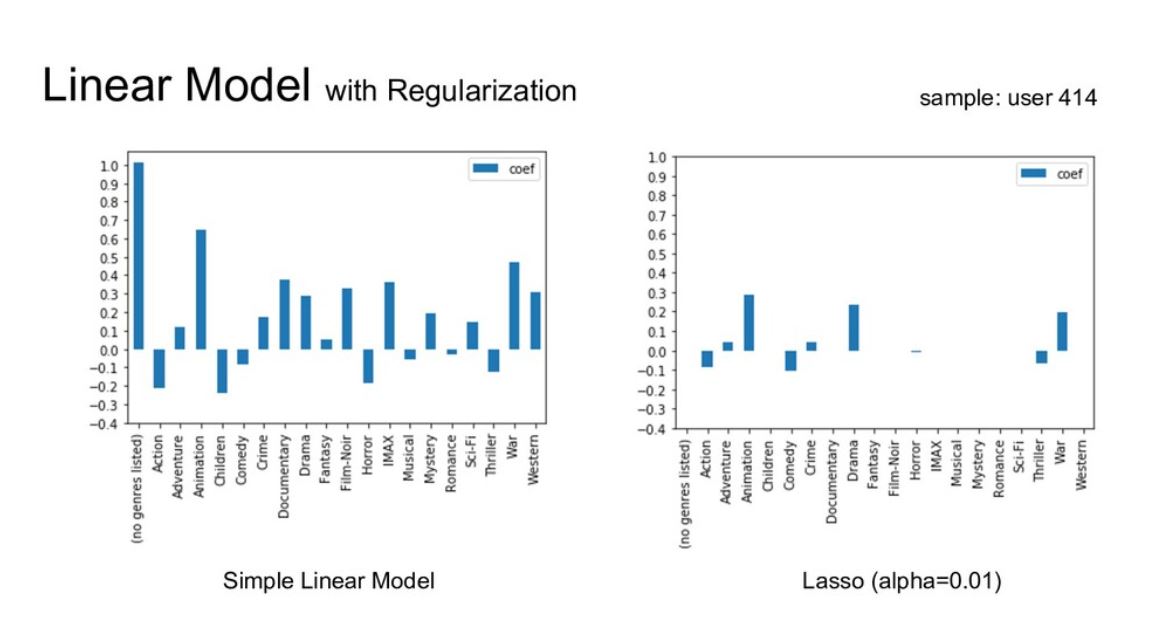
- coefficient 계수들의 크기가 줄어듬
- 쓸모 있는 변수들은 남기고 그렇지 않은 변수들을 제거하는게 탁월함(feature selection)
- Lasso 모델은 feature selection이 자동으로 됨
reg = Lasso(alpha=0.05)
reg.fit(x_train,y_train)
intercept = reg.intercept_
coef = reg.coef_
uesr_profile = pd.DataFrame([intercept, *coef], index=['intercept', *genres.columns], columns=['score'])
그래프로 보기
plt.figure(figsize=(25,7))
sns.barplot(data=uesr_profile.reset_index(), x='index', y='score')
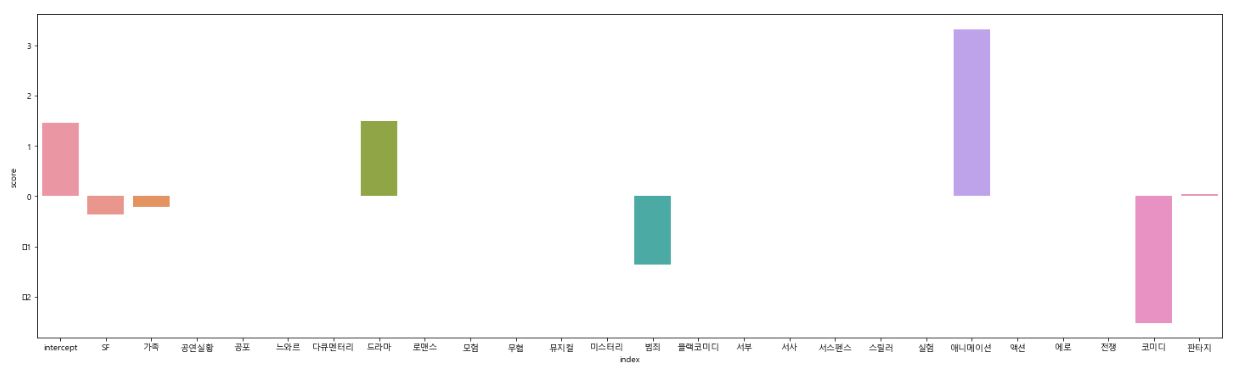
정규화 전보다 변수들이 많이 제거됨(feature selection)
RMSE(Root Mean Square Error)
predict = reg.predict(x_test)
mse = mean_squared_error(y_test,predict)
rmse = np.sqrt(mse)
# rmse = 0.5894064136626995
하이퍼 파라미터 튜닝
-
Lasso의 적절한 alpha을 구해주는 방법
model = Lasso()
param_grid = {'alpha' : sp_rand()}
# 150번 돌려봄
research = RandomizedSearchCV(estimator=model,
param_distributions=param_grid,
n_iter=150,
cv=10,
random_state=10 )
research.fit(tester[genres.columns], tester['score'])
# research.best_estimator_.alpha = 0.771320643266746
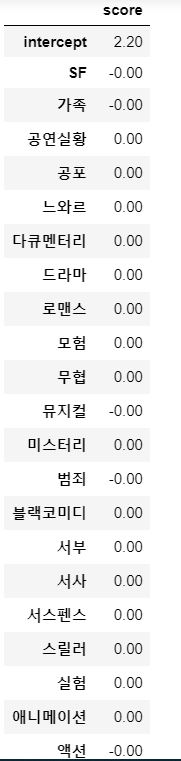
- RandomizedSearch 결과 : research.best_estimator_.alpha
- 최적의 alpha값 : 0.771320643266746
intercept = research.best_estimator_.intercept_
coef = research.best_estimator_.coef_
uesr_profile = pd.DataFrame([intercept, *coef], index=['intercept', *genres.columns], columns=['score'])
Comments