
추천 시스템(3) - Collarborate filtering 구현
[KNN 알고리즘으로 협업필터링 구현하기]
Table of Contents
-
협업 필터링 구현 (Collarborate filtering)
KNN 알고리즘
Install
pip install pandas
pip install numpy
pip install scipy
pip install surprise
Import
import pandas as pd
import numpy as np
import scipy as sp
import surprise
Read Data
data = pd.read_csv('./data/wouldyouci/ratings.csv')
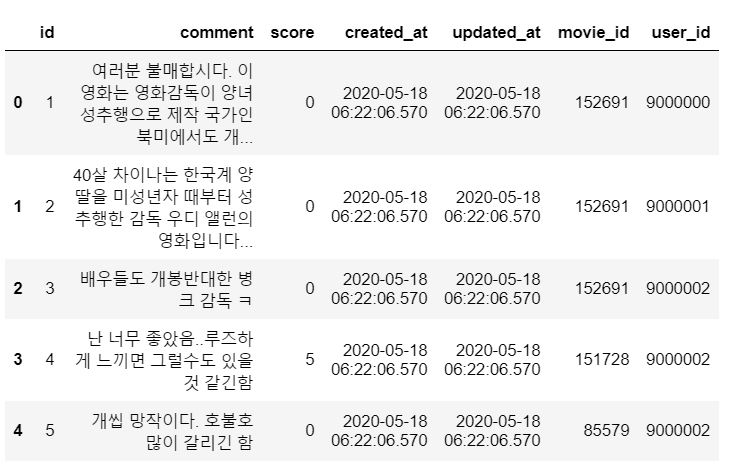
구현하기
1. Collaborative Filtering 추천 시스템에 필요한 변수만 선택
df = data[['user_id', 'movie_id', 'score']]
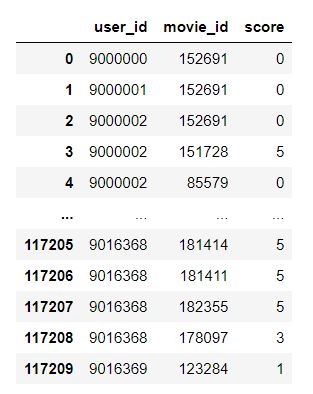
2. 데이터 변형(테이블 -> 딕셔너리)
# 테이블을 딕셔너리로 만드는 함수
def recur_dictify(frame):
if len(frame.columns) == 1:
if frame.values.size == 1: return frame.values[0][0]
return frame.values.squeeze()
grouped = frame.groupby(frame.columns[0])
d = {k: recur_dictify(g.iloc[:, 1:]) for k, g in grouped}
return d
- 보유한 데이터가 테이블 형태로 되어있는데, 추천시스템에 사용하기 위해서는 데이터를 딕셔너리 형태로 바꾸어 주어야 한다. 그래야 머신러닝 모델을 통해 나온 결과를 인덱싱해서 추천 영화 리스트로 뽑아낼 수 있다.
3. 최소개수 지정
n1 = 5
filter_movies = df['movie_id'].value_counts() >= n1
filter_movies = filter_movies[filter_movies].index.tolist()
n2 = 5
filter_users = df['user_id'].value_counts() >= n2
filter_users = filter_users[filter_users].index.tolist()
df_new = df[df['movie_id'].isin(filter_movies) & df['user_id'].isin(filter_users)]
# 테이블 -> 딕셔너리
df_to_dict = recur_dictify(df_new)

4. 사용자 목록, 영화 목록을 리스트로 담기
user_list = []
movie_set = set()
for user in df_to_dict:
user_list.append(user)
for movie in df_to_dict[user]:
movie_set.add(movie)
movie_list = list(movie_set)
5. 추천 시스템에 사용할 rating 딕셔너리 만들기
# 학습할 데이터를 준비한다.
rating_dic = {
'user_id': [],
'movie_id': [],
'score': []
}
# 유저 수 만큼 반복
for user in df_to_dict:
# 해당 유저의 리뷰 수 만큼 반복
for movie in df_to_dict[user]:
u_index = user_list.index(user)
m_index = movie_list.index(movie)
score = df_to_dict[user][movie]
rating_dic['user_id'].append(u_index)
rating_dic['movie_id'].append(m_index)
rating_dic['score'].append(score)
# 데이터셋 만들기
df = pd.DataFrame(rating_dic)
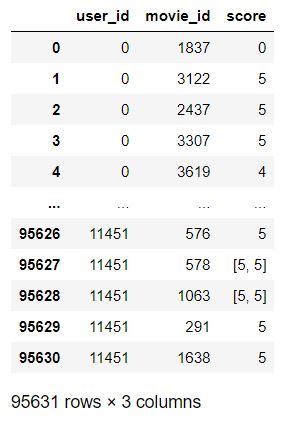
6. 학습 : surprise.KNNBasic
# 데이터를 읽어들이는 객체 생성 (rating scales : 평점 범위)
reader = surprise.Reader(rating_scale=(0.5, 5.0))
col_list = ['user_id', 'movie_id', 'score']
data = surprise.Dataset.load_from_df(df_new[col_list], reader)
# 학습
trainset = data.build_full_trainset()
algo = surprise.KNNBasic(sim_options=option)
algo.fit(trainset)
- 사용자간 유사도를 측정하는데에는 pearson similarity를 사용
7. 예측 : KNN(K-Nearest Neighbor) 알고리즘
# user_id = 9000002
index = user_list.index(9000002)
result = algo.get_neighbors(index, k=5)
- user_id가 9000002인 유저의 이웃 K명을 구함
- result = [828, 904, 1187, 1386, 1416]
8. Pickle 파일로 저장
recommand_dic = {
'user_id': [],
'movie_id': [],
}
for user_key in df_new['user_id'].unique():
index = user_list.index(user_key)
result = algo.get_neighbors(index, k=5)
recom_set = set()
for i in result:
max_rating = data.df[data.df['user_id'] == user_list[i]]['score'].max()
recom_movies = data.df[(data.df['score'] == max_rating) & (data.df['user_id'] == user_list[i])][
'movie_id'].values
for item in recom_movies:
recom_set.add(item)
for item in recom_set:
recommand_dic['user_id'].append(user_key)
recommand_dic['movie_id'].append(item)
pickle = pd.DataFrame(recommand_dic)
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
path = os.path.join(BASE_DIR, 'KNN.p')
pd.to_pickle(pickle, path)
- K=5로 설정되어서 유사한 유저 5명을 기반으로 영화를 추천해주게 된다.
- 유사한 유저들이 가장 높은 점수를 준 영화 목록을 set에 넣는다
- 해당 유저에게 추천하는 영화 리스트를 Pickle 파일로 저장
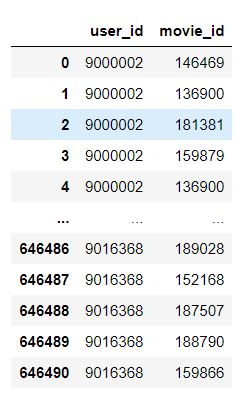
9. Pickle 파일에서 바로 꺼내쓰기(user_id = 9000002)
user_id = 9000002
path = os.path.join(settings.BASE_DIR, 'utils', 'KNN.p')
df = pd.read_pickle(path)
movie_list = df.loc[df['user_id'] == user_id, 'movie_id'].unique()
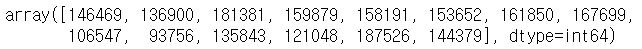
Comments